Power BI供应链数据分析可视化产品构建与数据处理全流程解析
随着企业供应链日益复杂,数据驱动的决策变得至关重要。Power BI作为微软推出的强大商业智能工具,能够帮助企业构建直观、交互式的供应链数据分析可视化产品,从而优化库存、提升物流效率并降低运营成本。本文将系统阐述基于Power BI构建供应链可视化产品的核心流程,并重点解析数据处理这一关键环节。
一、构建供应链可视化产品的整体框架
一个完整的供应链数据分析可视化产品通常涵盖以下模块:
- 需求预测与计划:通过历史销售数据、市场趋势进行需求分析。
- 采购与供应商管理:监控供应商绩效、采购成本与交货准时率。
- 库存优化:分析库存周转率、安全库存水平及呆滞库存情况。
- 物流与配送:跟踪运输成本、配送时效与路线效率。
- 整体供应链绩效:通过关键绩效指标(KPI)仪表板综合评估供应链健康度。
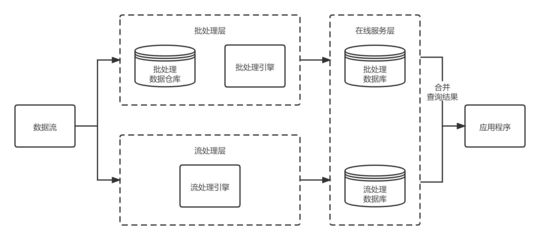
二、数据处理:可视化产品的基石
在Power BI中,数据处理是构建可靠可视化产品的前提,主要分为以下步骤:
1. 数据源连接与获取
供应链数据通常分散在多个系统中,如ERP(如SAP、Oracle)、WMS(仓库管理系统)、TMS(运输管理系统)以及Excel、CSV文件等。Power BI支持连接这些异构数据源,并通过Power Query实现数据的集中提取。
2. 数据清洗与转换
这是数据处理中最耗时的环节,旨在确保数据质量。常见操作包括:
- 消除重复项与错误值:如删除重复的交易记录,修正错误的库存数量。
- 格式标准化:统一日期格式、货币单位及产品编码。
- 处理缺失值:通过填充默认值或插值方法补全缺失的供应商交货时间。
- 数据透视与逆透视:将宽表转换为适合分析的窄表结构。
3. 数据建模与关系建立
清洗后的数据需要在Power BI中建立数据模型:
- 创建维度表与事实表:例如,产品表、供应商表、时间表为维度表;采购订单表、库存交易表为事实表。
- 建立表关系:通过主键和外键(如产品ID、供应商ID)连接维度表与事实表,形成星型或雪花型模型,确保数据分析的准确性。
4. 度量值与计算列的创建
利用DAX(数据分析表达式)语言增强分析能力:
- 计算列:在数据表中新增列,如根据采购日期和交货日期计算“交货延迟天数”。
- 度量值:动态计算聚合指标,如“库存周转率 = 总销售成本 / 平均库存价值”。
- 时间智能函数:进行同比、环比分析,如“本月库存水平 vs 上月”。
5. 数据刷新与自动化
为确保可视化产品反映最新状态,需配置数据刷新计划:
- 对于云端数据源(如Azure SQL Database),可直接在Power BI服务中设置定时刷新。
- 对于本地数据源(如企业内网数据库),需通过Power BI网关建立安全连接,实现数据同步。
三、可视化设计与交互
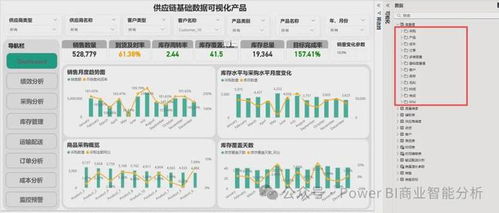
在坚实的数据处理基础上,设计直观的可视化报表:
- 选用合适的视觉对象:如使用地图展示供应商与仓库分布,折线图显示需求趋势,仪表显示库存满足率。
- 创建交互式钻取:允许用户从国家层级下钻到区域、仓库,甚至具体产品。
- 整合自然语言问答:用户可直接提问,如“上季度运输成本最高的路线是哪些?”,Power BI将自动生成相应可视化。
四、最佳实践与挑战应对
- 性能优化:对大型数据集使用聚合表或导入模式而非直接查询,提升报表响应速度。
- 数据安全:通过行级安全性(RLS)控制不同用户(如采购经理、物流主管)的数据访问权限。
- 持续迭代:根据业务反馈不断调整数据模型与可视化,使产品更贴合决策需求。
Power BI供应链数据分析可视化产品的构建是一个从数据到洞察的闭环过程。其中,数据处理作为底层支撑,决定了可视化产品的准确性与可靠性。通过系统性的数据连接、清洗、建模与刷新,企业能够将分散、原始的供应链数据转化为直观、 actionable 的视觉洞察,最终驱动供应链的智能化管理与卓越运营。
如若转载,请注明出处:http://www.maiyishangcheng.com/product/8.html
更新时间:2026-06-18 16:33:56