基于Spark与Hadoop的新疆特产电商销售数据联动分析系统
随着电子商务的蓬勃发展与大数据技术的广泛应用,利用先进的数据处理与分析框架对区域特色产品销售数据进行深度挖掘,已成为提升运营效率、洞察市场趋势的关键。本文旨在探讨构建一个集数据采集、处理、分析与可视化于一体的联动分析系统,该系统以Hadoop为底层分布式存储与计算基础,以Spark为高性能核心处理引擎,专注于新疆特产电商销售数据的全流程处理与智能分析。
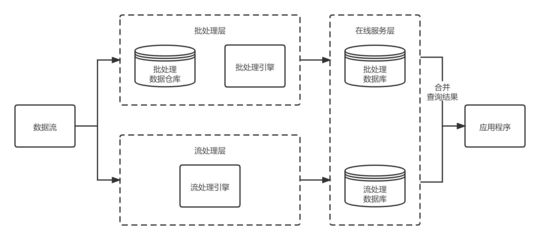
一、 系统架构与数据处理流程
本系统采用分层架构设计,旨在实现高可扩展性、高吞吐量与低延迟分析。
- 数据采集层:系统从多个源头采集数据,包括电商平台(如淘宝、京东)的交易订单、用户评价、商品详情,以及企业内部ERP系统的库存、物流信息。数据格式涵盖结构化数据(MySQL、PostgreSQL)和半结构化/非结构化数据(JSON日志、文本评论)。Apache Flume和Kafka常用于构建实时或准实时数据采集管道,将数据流式导入下一层。
- 分布式存储层(基于Hadoop):采集到的原始数据统一存入Hadoop分布式文件系统(HDFS)中。HDFS提供了海量、高容错、低成本的存储能力,是构建大数据湖的基石。我们将原始数据、清洗后的数据以及处理过程中的中间数据分层存储于HDFS的不同目录下,便于管理和后续处理。Hadoop YARN作为集群资源管理器,负责协调计算资源。
- 核心计算与处理层(基于Spark):这是系统的核心。Spark凭借其内存计算、DAG执行引擎和丰富的API(RDD, DataFrame, SQL, MLlib, GraphX),高效地承担了绝大部分数据处理与分析任务。其处理流程主要包括:
- 数据清洗与集成:利用Spark SQL和DataFrame API,对HDFS中的原始数据进行清洗,包括处理缺失值、异常值、格式标准化,并将来自不同源的数据根据关键字段(如商品ID、订单ID)进行关联与集成,形成宽表。
- 数据转换与聚合:根据分析需求,对清洗后的数据进行复杂的转换和聚合操作。例如,按时间(日/月/季度)、地区、特产品类(如红枣、葡萄干、核桃、哈密瓜制品)等多个维度统计销售额、销售量、客单价、复购率等关键指标。Spark的高性能迭代计算能力在此环节优势明显。
- 数据分析与挖掘:利用Spark MLlib机器学习库,可以进行更深层次的分析,如用户分群(聚类分析)、热销商品关联规则挖掘(Apriori算法)、销售额预测(时间序列分析或回归模型)等,为精准营销和库存管理提供数据洞察。
- 数据服务与存储层:经过Spark处理后的高价值结果数据,根据其使用场景,可以输出到不同的存储系统中:
- 需要支持实时查询和报表的聚合结果(如每日销售大盘),可写入Hive数据仓库或HBase数据库中。
- 需要供前端可视化系统快速读取的指标数据,可导出到关系型数据库(如MySQL)或高性能分析型数据库(如ClickHouse)中。
- 模型训练得到的参数或预测结果也可存回HDFS或特定数据库。
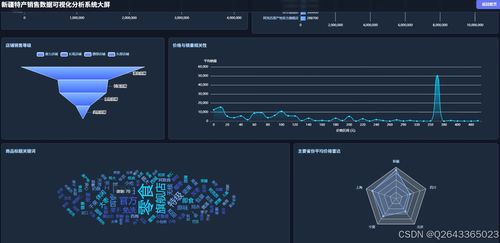
- 数据可视化与应用层:基于处理后的结果数据,构建可视化分析仪表板。可以使用如ECharts、AntV等前端图表库,或集成Superset、Metabase等开源BI工具。可视化内容涵盖:
- 销售全景看板:实时销售总额、订单量、核心品类占比地图(突出新疆各地州特产销售分布)。
- 趋势分析:各类特产销售额、销量随时间(年/月/日)的变化趋势曲线。
- 用户画像分析:购买新疆特产的用户地域分布、消费层级、偏好品类分析。
- 商品关联与排行:热销商品组合、单品销量/销售额排行榜。
- 预测仪表盘:基于机器学习模型对未来销售趋势的预测展示。
二、 “联动分析”的核心体现
本系统的“联动”特性主要体现在两个方面:
- 技术栈联动:Hadoop与Spark的深度融合。Hadoop HDFS提供了可靠的、海量的数据存储底座,而Spark则以其卓越的内存计算能力高效处理HDFS上的数据,两者通过YARN进行资源协同。这种组合克服了传统MapReduce计算模型迭代效率低下的问题,实现了批处理与流处理的统一,既能进行历史全量数据的深度挖掘,也能支持近实时的销售数据微批处理分析。
- 分析维度联动:系统支持多维度、可交互的联动分析。在可视化界面中,用户点击地图上的某个地州(如吐鲁番),仪表板上的销售趋势图、商品排行等会联动刷新,仅显示该地州特产(如葡萄干)的销售数据;反之,选择某个特定品类,地图上也会高亮显示出该品类的主要销售来源地区。这种钻取、切片、关联的互动分析能力,使得业务人员能够从宏观到微观,快速定位问题、发现商机。
三、
构建基于Spark与Hadoop的新疆特产电商销售数据联动分析系统,能够有效整合多源异构数据,利用强大的分布式计算能力,将原始数据转化为直观、多维、可交互的商业洞察。该系统不仅有助于新疆特产电商企业实时掌握经营状况,精准评估营销效果,优化选品与库存策略,还能从宏观层面分析市场需求与区域偏好,为新疆特色农业的数字化、品牌化发展提供有力的数据支撑。通过持续迭代数据处理模型与分析算法,该系统将成为一个智能化的决策辅助中枢,驱动业务持续增长。
如若转载,请注明出处:http://www.maiyishangcheng.com/product/15.html
更新时间:2026-06-18 12:34:18